파인튜닝 훈련 : 모델을 파인튜닝 데이터셋을 사용하여 훈련합니다. 이 과정에서 모델의 가중치가 새로운 데이터에 맞게 조정됩니다.
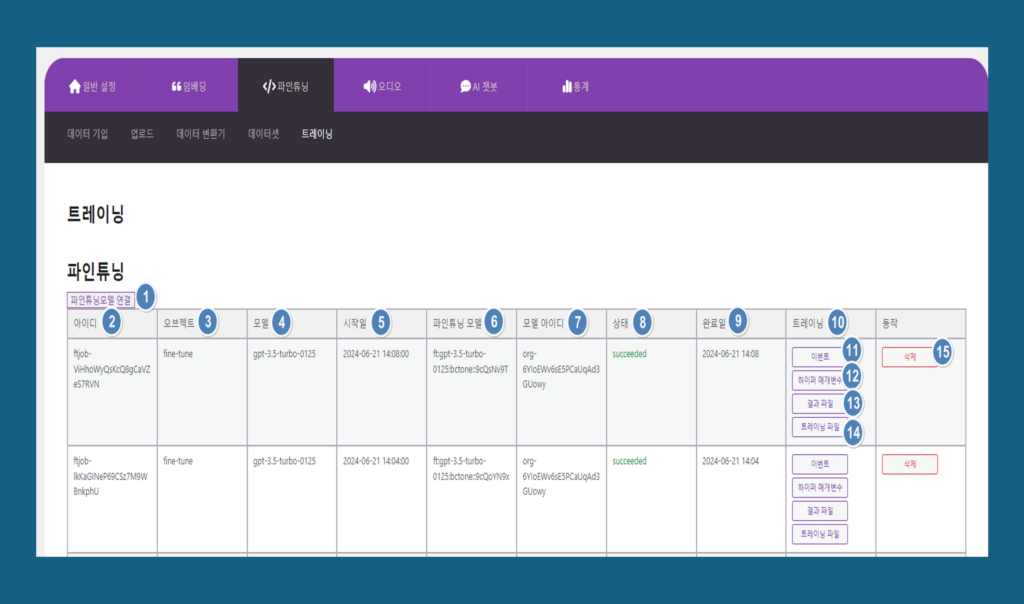
1.파인튜닝모델 연결 : 전 단계인 데이터 셋 탭에서 ‘파인튜닝 생성’ 버튼을 누르면 트레이닝 탭에서 해당 리스트가 생성된 것을 확인 할 수 있습니다.
2. 아이디 : 파인튜닝 작업의 고유 식별자로 사용됩니다. 모델의 이름 또는 고유한 식별 번호를 사용할 수 있습니다.
3. 오브젝트 : 오브젝트는 파인튜닝으로 표시됩니다.
4. 모델: 파인튜닝할 기본 모델입니다. 사전 훈련된 모델을 가져와서 특정 작업에 맞게 조정합니다.
5. 시작일: 파인튜닝 작업이 시작되는 날짜를 지정합니다. 프로젝트의 일정 관리 및 기록을 위해 필요합니다.
6. 파인튜닝 모델 : 파인튜닝할 커스텀 사전 훈련된 모델을 의미합니다. 이 모델은 특정 작업을 위해 추가로 훈련됩니다.
7. 모델 아이디 (Model ID) : 특정 파인튜닝 모델을 식별하기 위한 고유한 ID입니다. 모델 관리와 추적을 위해 사용됩니다.
8. 상태: 파인튜닝을 처리한 결과가 표시됩니다. 실패(Failed)와 성공(Succeeded) 으로 표시됩니다.
9. 완료일: 파인튜닝 작업이 완료된 날짜입니다. 프로젝트 관리 및 기록을 위해 필요합니다.
10. 트레이닝: 트레이닝에는 이벤트, 하이퍼 매개변수, 결과 파일, 트레이닝 파일이 있습니다.
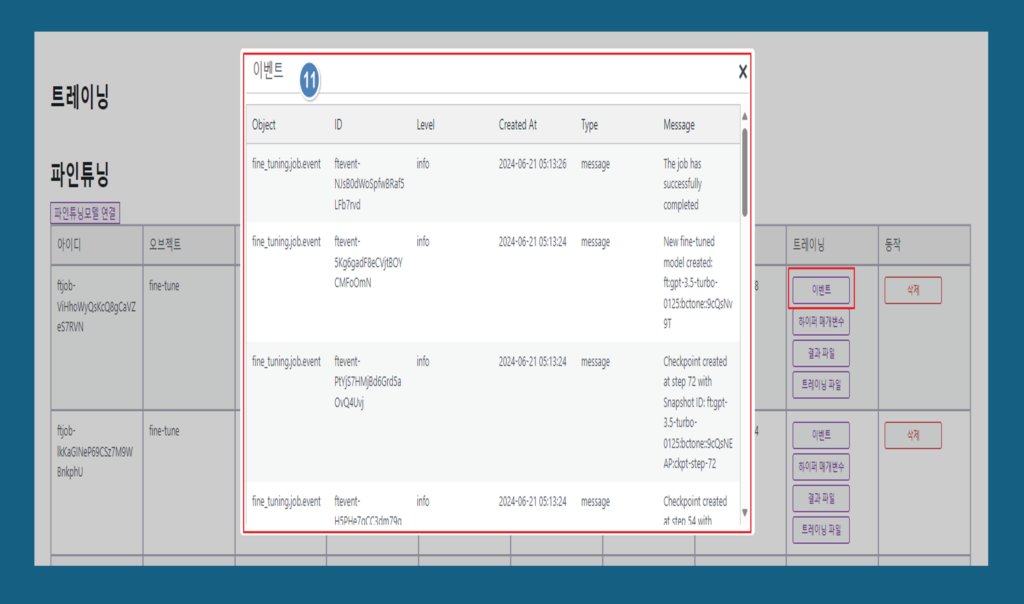
11. 이벤트: 파인튜닝 과정에서 발생하는 주요 이벤트를 기록합니다. 이벤트 로그는 문제 해결 및 모델 개선에 도움이 됩니다.
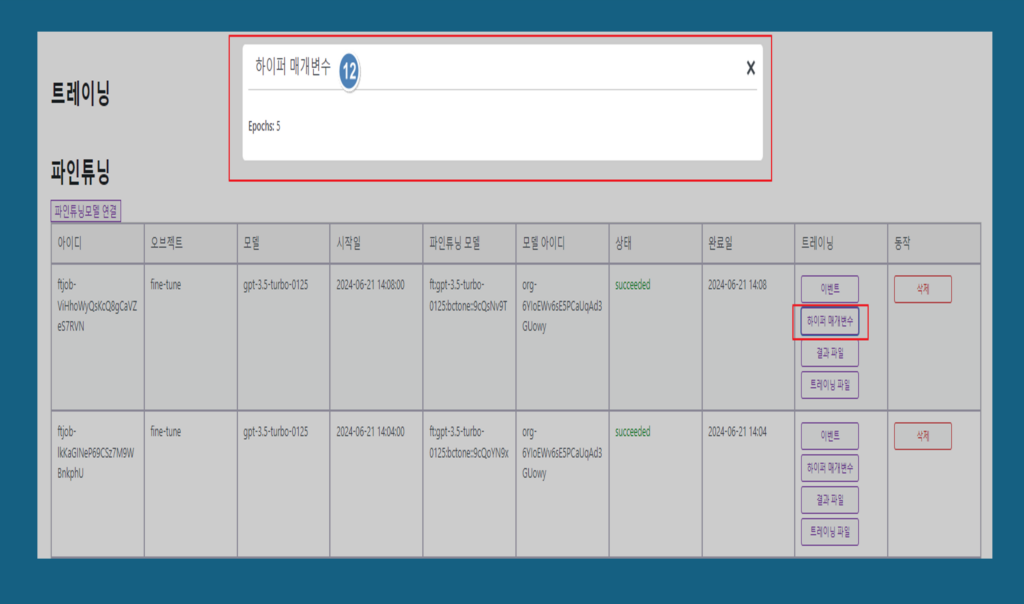
12. 하이퍼 매개변수 : 파인튜닝 과정에서 사용하는 설정값들로, 모델의 성능에 중요한 영향을 미칩니다.에포크는 전체 훈련 데이터셋이 모델을 통해 한 번 완전히 전달된 횟수를 의미합니다. 에포크는 전체 훈련 데이터셋의 반복 횟수를 의미합니다. 모델은 각 에포크마다 데이터를 학습하고, 손실 함수(loss function)를 통해 예측과 실제 값 간의 차이를 계산합니다. 옵티마이저(optimizer)는 손실을 줄이기 위해 모델의 가중치를 업데이트합니다.여러 에포크 동안 모델은 점차적으로 학습하여 예측 성능을 향상시킵니다.
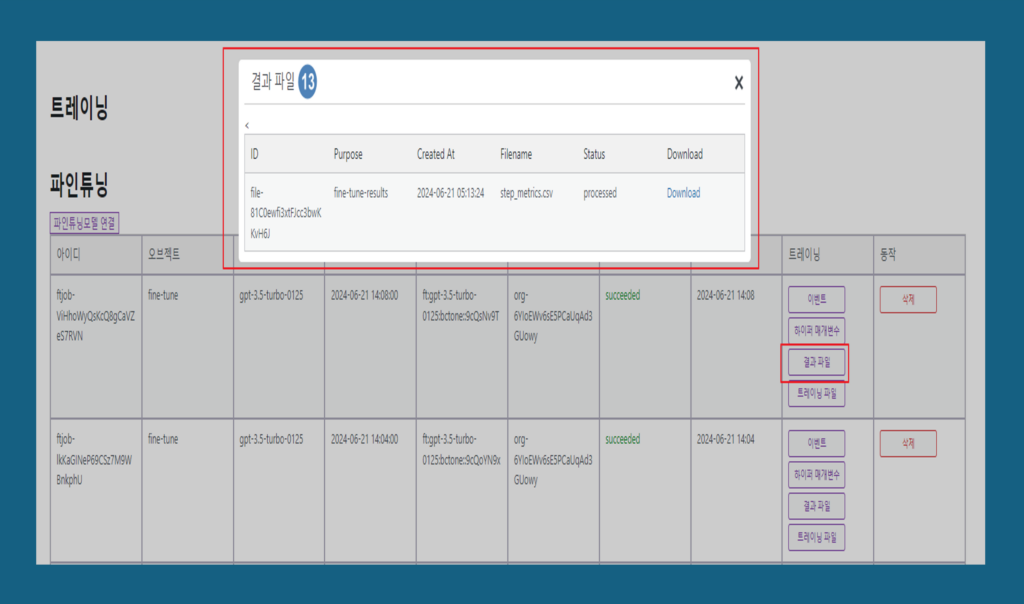
13. 결과 파일: 결과파일은 모델 훈련 과정이 끝난 후 생성되는 파일들로, 훈련된 모델과 학습 과정의 다양한 정보를 담고 있습니다. 이러한 파일들은 모델 평가, 배포, 및 재훈련에 유용하게 사용됩니다.
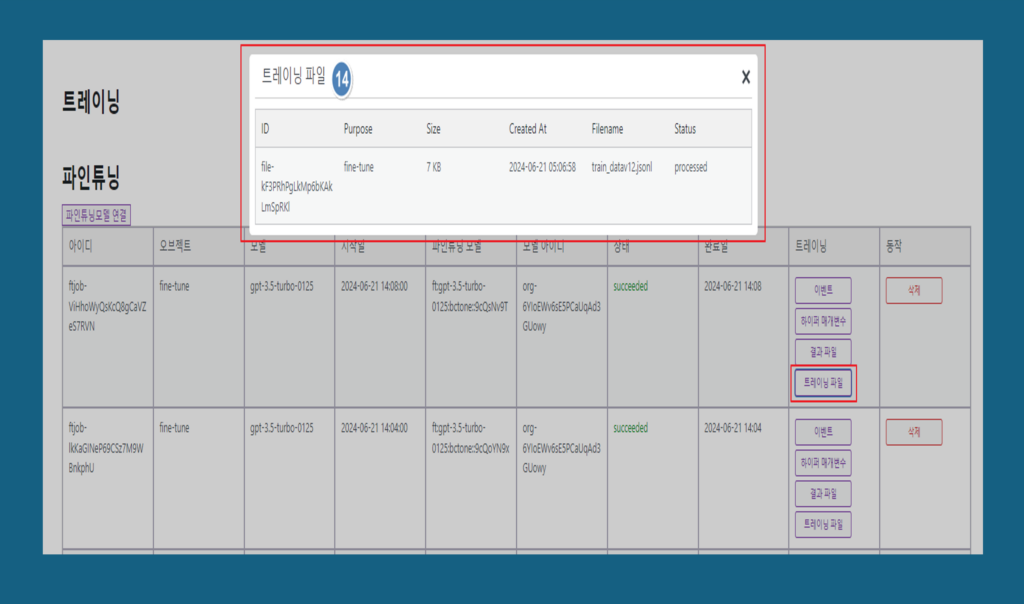
14. 트레이닝 파일 : 모델 훈련 과정이 끝난 후 생성되는 파일들로, 훈련된 모델과 학습 과정의 다양한 정보를 담고 있습니다. 이러한 파일들은 모델 평가, 배포, 및 재훈련에 유용하게 사용됩니다.
15. 삭제 : 삭제 버튼을 누르면 행에서 해당 파인튜닝 처리된 부분이 삭제 처리됩니다.
